China’s cheap, open AI model DeepSeek thrills scientists
DeepSeek-R1 performs reasoning tasks at the same level as OpenAI’s o1 — and is open for researchers to examine.
By Elizabeth Gibney
A Chinese-built large language model called DeepSeek-R1 is thrilling scientists as an affordable and open rival to ‘reasoning’ models such as OpenAI’s o1.
These models generate responses step-by-step, in a process analogous to human reasoning. This makes them more adept than earlier language models at solving scientific problems and could make them useful in research. Initial tests of R1, released on 20 January, show that its performance on certain tasks in chemistry, mathematics and coding is on par with that of o1 — which wowed researchers when it was released by OpenAI in September.
“This is wild and totally unexpected,” Elvis Saravia, an AI researcher and co-founder of the UK-based AI consulting firm DAIR.AI, wrote on X.
R1 stands out for another reason. DeepSeek, the start-up in Hangzhou that built the model, has released it as ‘open-weight’, meaning that researchers can study and build on the algorithm. Published under an MIT licence, the model can be freely reused but is not considered fully open source, because its training data has not been made available.
“The openness of DeepSeek is quite remarkable,” says Mario Krenn, leader of the Artificial Scientist Lab at the Max Planck Institute for the Science of Light in Erlangen, Germany. By comparison, o1 and other models built by OpenAI in San Francisco, California, including its latest effort o3 are “essentially black boxes”, he says.
DeepSeek hasn’t released the full cost of training R1, but it is charging users around one-thirtieth of what o1 costs to run. The firm has also created mini ‘distilled’ versions of R1 to allow researchers with limited computing power to play with the model. An “experiment that cost more than £300 with o1, cost less than $10 with R1,” says Krenn. “This is a dramatic difference which will certainly play a role its future adoption.”
Challenge models
R1 is the part of a boom in Chinese large language models (LLMs). Spun out of a hedge fund, DeepSeek emerged from relative obscurity last month when it released a chatbot called V3, which outperformed major rivals, despite being built on a shoestring budget. Experts estimate that it cost around $6 million to rent the hardware needed to train the model, compared with upwards of $60 million for Meta’s Llama 3.1 405B, which used 11 times the computing resources.
Part of the buzz around DeepSeek is that it has succeeded in making R1 despite US export controls that limit Chinese firms’ access to the best computer chips designed for AI processing. “The fact that it comes out of China shows that being efficient with your resources matters more than compute scale alone,” says François Chollet, an AI researcher in Seattle, Washington.
DeepSeek’s progress suggests that “the perceived lead [the] US once had has narrowed significantly,” wrote Alvin Wang Graylin, a technology expert in Bellevue, Washington, who works at the Taiwan-based immersive technology firm HTC, on X. “The two countries need to pursue a collaborative approach to building advanced AI vs continuing on the current no-win arms race approach.”
Chain of thought
LLMs train on billions of samples of text, snipping them into word-parts called ‘tokens’ and learning patterns in the data. These associations allow the model to predict subsequent tokens in a sentence. But LLMs are prone to inventing facts, a phenomenon called ‘hallucination’, and often struggle to reason through problems.
Like o1, R1 uses a ‘chain of thought’ method to improve an LLM’s ability to solve more complex tasks, including sometimes backtracking and evaluating its approach. DeepSeek made R1 by ‘fine-tuning’ V3 using reinforcement learning, which rewarded the model for reaching a correct answer and for working through problems in a way that outlined its ‘thinking’.
Source: DeepSeek
Having limited computing power drove the firm to “innovate algorithmically”, says Wenda Li, an AI researcher at the University of Edinburgh, UK. During reinforcement learning the team estimated the model’s progress at each stage, rather evaluating it using a separate network. This helped to reduce training and running costs, says Mateja Jamnik, a computer scientist at the University of Cambridge, UK. The researchers also used a ‘mixture-of-experts’ architecture, which allows the model to activate only the parts of itself that are relevant for each task.
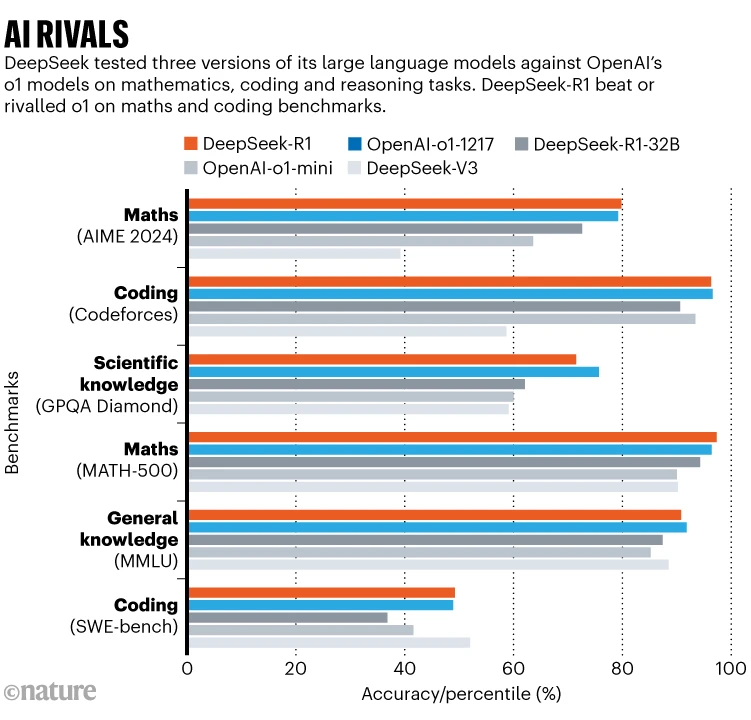
In benchmark tests, reported in a technical paper accompanying the model, DeepSeek-R1 scored 97.3% on the MATH-500 set of mathematics problems created by OpenAI and outperformed 96.3% of human participants in the Codeforces competition. These are on on par with o1’s abilities; o3 was not included in the comparisons (see ‘AI rivals’).
It is hard to tell whether benchmarks capture a model’s true ability to reason or generalize, or merely to pass such tests. But because R1 is open, its chain-of-thought is accessible to researchers, says Marco Dos Santos, a computer scientist at the University of Cambridge. “This allows better interpretability of the model’s reasoning processes,” he says.
Already, scientists are testing R1’s abilities. Krenn challenged both rival models to sort 3,000 research ideas by how interesting they are and compared the results with human-made rankings. On this measure, R1 slightly underperformed compared with o1. But R1 beat o1 on certain computations in quantum optics, says Krenn. “This is quite impressive.”
https://www.nature.com/articles/d41586-025-00229-6
OpenAI mau IPO, valuasinya sebelumnya 80 milliar dollar kalau tak salah, sekarang Deepseek muncul, apa masih segitu valuasinya?
the race is on